Token-efficient MCP servers part 1: lazy loading input schemas
Bloated to goated: how lazy loading can reduce context by an order of magnitude without sacrificing functionality.

April 23, 2025
Bloated tools
An MCP server tool is defined by its name, description and input schema, which describes the parameters the tool accepts. When a tool is registered by an MCP client, all this information gets injected into the system prompt - that's how the client LLM is aware of the tools available.
With LLM context windows growing to millions of tokens, chucking a few tools in the system prompt is a drop in the ocean, and you can get away with quite a lot. However, if you're trying to load tools encompassing entire web API functionality, things get impractical fast. For large APIs, the specification files like openapi.json and openrpc.json (which contain the input schemas for each operation) can easily reach millions of tokens.
Tool management is a related issue which we'll explore in a future post
Deeply nested schemas
The main culprit for tool bloat is deeply nested input schemas. Imagine we're turning a POST operation from Stripe's API into an MCP tool. Our job is to create a tool with input parameters which we can parse into a request body to then send to the appropriate Stripe endpoint. For creating a payment, here's what the schema for that request body looks like:

Schema describing the body of a single POST request to Stripe API (10,000 tokens)
Yikes. If we use that as the input schema we'd be 10k tokens down, just for defining one tool. We could do that, but it seems wasteful. Stripe's API has over 500 operations, so to load them all as tools would mean millions of tokens in the system prompt, before we've even started interacting with the tools.
Hierarchical scanning
What does a human developer do when reading the docs? Answer: browse the top-level properties first. In fact, docs pages usually collapse the schemas so at first glance we can only see the top-level properties. If a property looks useful, we click to expand, like this:
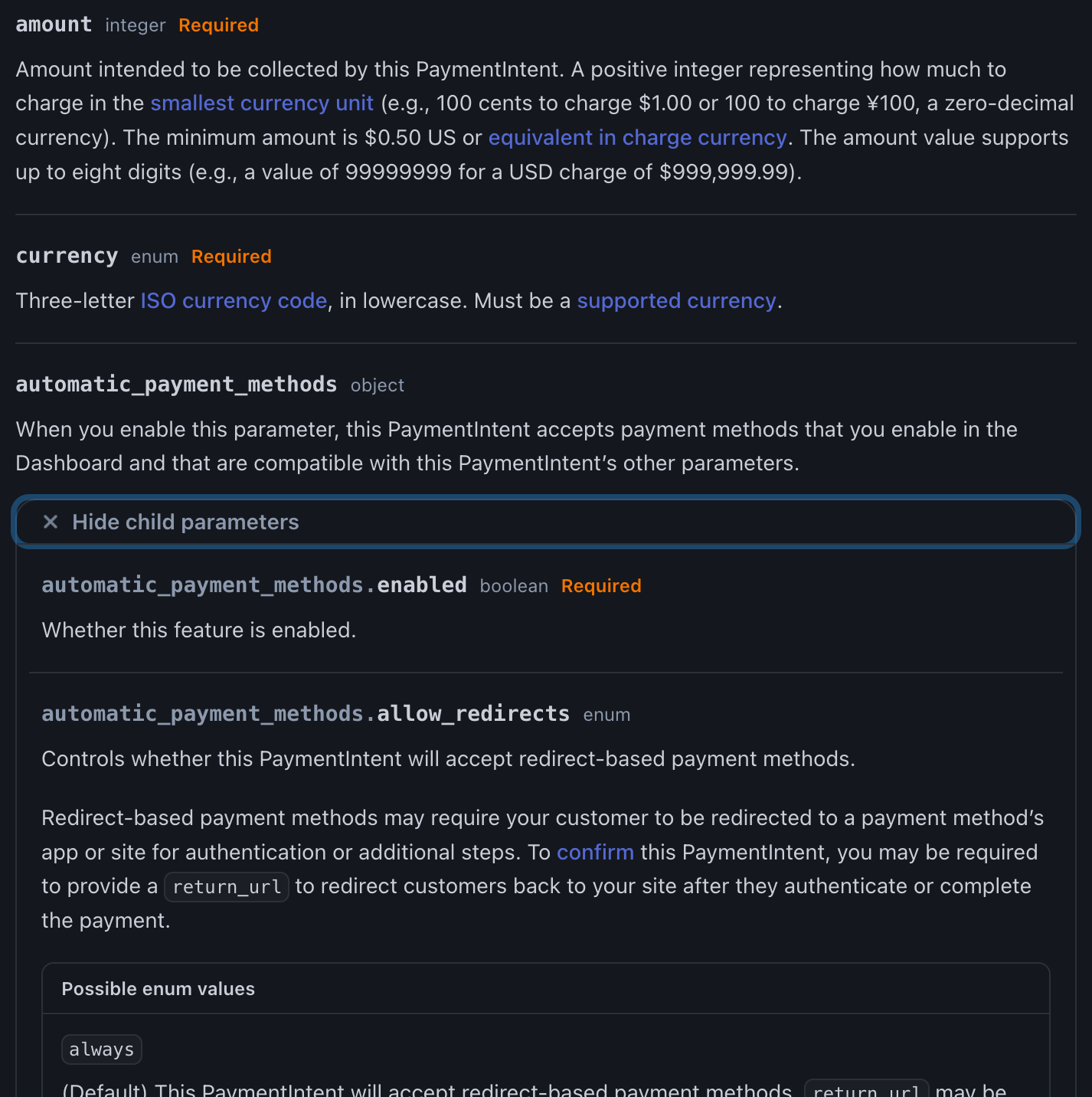
Stripe docs for Create PaymentIntent with automatic_payment_methods expanded
We then scan the child properties and if any of them look useful, we expand again. And so on, until we have what we need.
Lazy loading partial schemas
So how can we get our MCP client to do the same as a human developer would? Imagine if our MCP tools had input schemas containing top-level properties only, with any nested properties truncated:
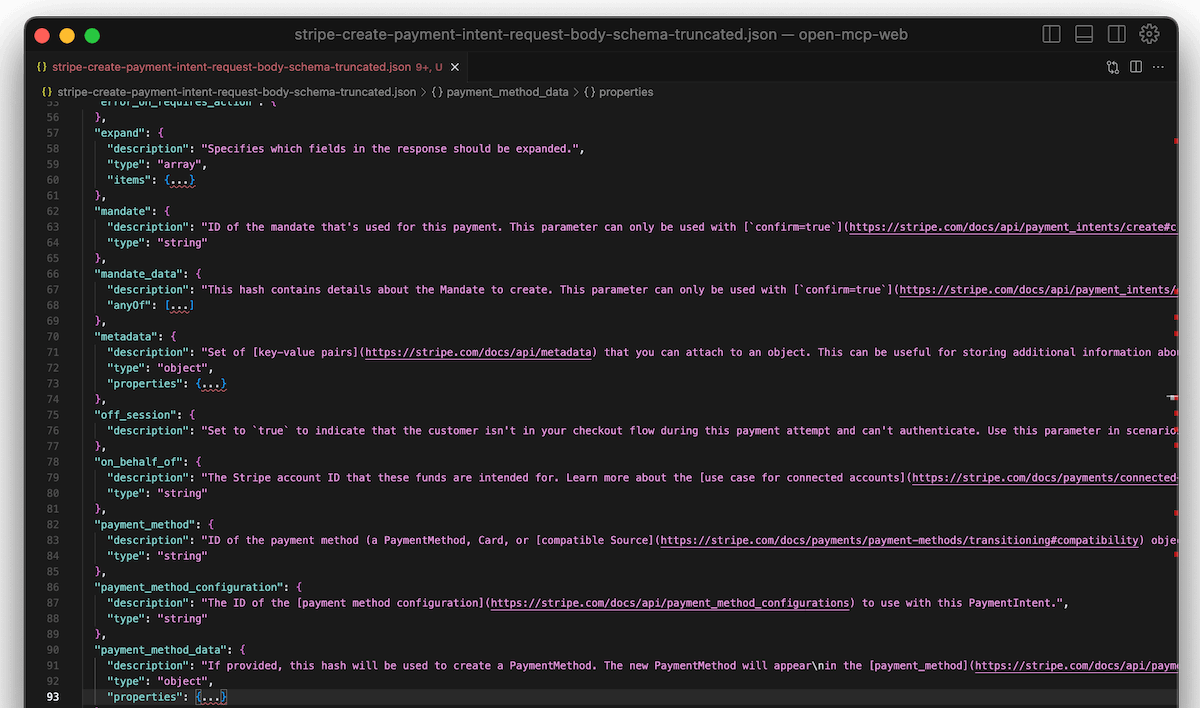
The Create PaymentIntent request body schema with nested properties truncated e.g. expand, mandate_data, metadata etc.
There are ~30 top-level properties in this schema which is still quite a lot for one tool but much more manageable - it's an order of magnitude smaller than the enormous schema we had to start with. The client now has a good sense of what properties are available, without being overwhelmed by all the unnecessary details.
But what if the client wants to use one of these truncated properties when calling the tool? With only the top-level parameters visible, it doesn't have much to go on to reliably produce correctly formatted input parameters.
Tree partitioning schemas
Suppose the MCP server stores the full input schemas, but partitioned into chunks so each chunk is only one level deep. The MCP can now provide the client with a tool or resource to allow fetching specific chunks of the schema tree. The client can browse the top-level first, as humans do, then iteratively request deeper properties until it has fully traversed the parts of the tree it needs for the task in hand:
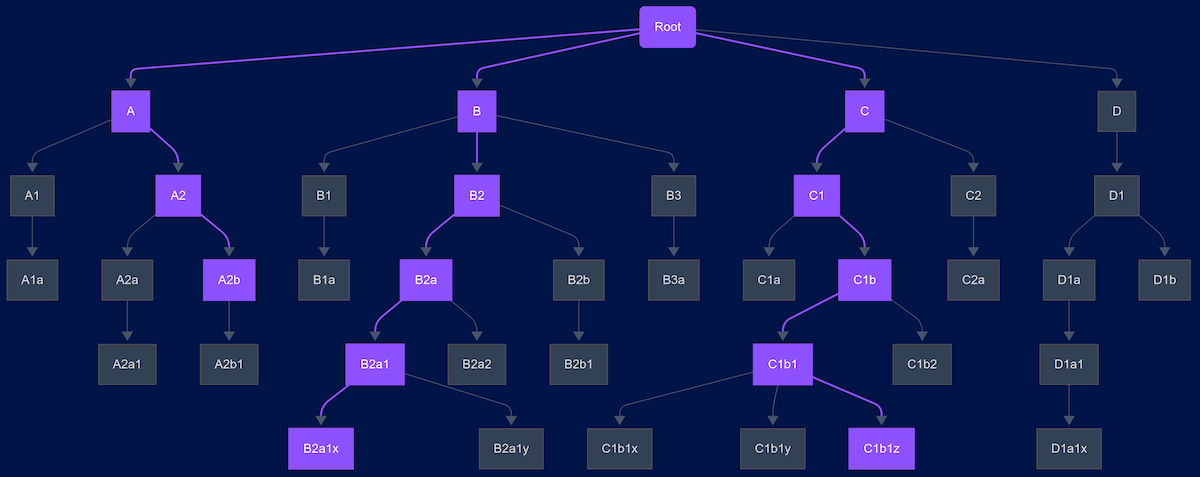
For a given task the client requests parts of the schema highlighted in purple
No loss of information
The lazy loading approach ensures there's no loss of information compared to loading the entire schema upfront. While the client needs multiple round trips to the MCP server to fetch deep parts of the schema, the server is just returning static, cached content so it's fast and doesn't add much overhead to the process. For this minor sacrifice we've kept complete functionality of the underlying web API while cutting the initial context size by an order of magnitude. All the data is available when needed, but we're not paying the token cost until that moment arrives. The result is an efficient MCP server that provides the full functionality of a complex API without overwhelming the client's context window.
OpenMCP standard
Every OpenMCP server has appropriately partitioned input schemas and an expandSchema tool which empowers the client to get what it needs, when it needs it. This standardised approach ensures that all MCP servers, regardless of the underlying API they're derived from, provide a consistent and efficient experience. By implementing lazy loading as a core feature, OpenMCP makes even the most complex APIs with millions of schema tokens accessible without bloating the client's system prompt. The client maintains full control over which parts of the input schemas to explore, enabling natural discovery of API capabilities while preserving token efficiency.
Get started
Try lazy loading out yourself by following the links below: